Pagina web a norma
Pagina web a norma Avere una pagina web oggi è cosa comune. Molto spesso purtroppo ci ritroviamo di fronte a pagine…
SEO, acronimo di Search Engine Optimization, è il processo di ottimizzazione di un sito web per ottenere una migliore visibilità e classificazione nei risultati dei motori di ricerca. Questa pratica comprende una serie di tecniche finalizzate a migliorare la qualità e la pertinenza del contenuto del sito, nonché la sua struttura e la sua autorità online.
Tra le tecniche di SEO più comuni vi sono l’ottimizzazione delle parole chiave, l’ottimizzazione dei titoli e delle descrizioni delle pagine, l’ottimizzazione dei tag di intestazione e dei tag meta, nonché la creazione di contenuti di alta qualità e rilevanti per il pubblico di riferimento. Inoltre, la SEO include anche la gestione dei link interni ed esterni, la velocità di caricamento delle pagine e l’ottimizzazione per dispositivi mobili.
L’obiettivo della SEO è migliorare la visibilità del sito web nei motori di ricerca, aumentare il traffico organico e generare più conversioni e vendite. Una buona strategia di SEO può aiutare un sito web a raggiungere una posizione prominente nei risultati di ricerca per determinate parole chiave o argomenti, aumentando così la sua autorità e la sua reputazione online.
Tuttavia, la SEO è un processo continuo e richiede un monitoraggio costante delle prestazioni del sito web, nonché l’adattamento alle modifiche negli algoritmi dei motori di ricerca. È importante mantenere una strategia di SEO aggiornata e in linea con le migliori pratiche per assicurare risultati duraturi e sostenibili nel tempo.
In conclusione, la SEO è un componente essenziale per il successo di un sito web online. Ottimizzare un sito web per i motori di ricerca può migliorare la sua visibilità, il traffico organico e le conversioni, contribuendo a raggiungere gli obiettivi di business e a consolidare la sua presenza online.
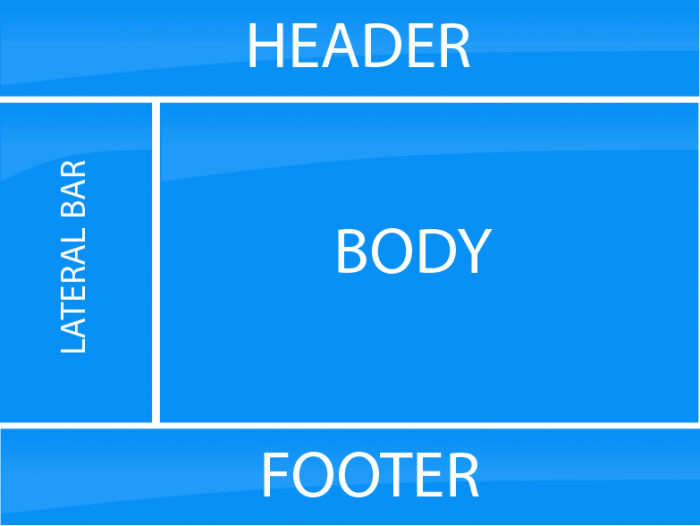
Pagina web a norma Avere una pagina web oggi è cosa comune. Molto spesso purtroppo ci ritroviamo di fronte a pagine…
web scraping! cos’è ? L’argomento del post riguarda le cose da sapere sulla indicizzazione nei motori di ricerca di una pagina…